
Security takes a layered approach to reduce the risk to our organization. Input validation is the perfect example of one of these layers. In most cases, input validation is 1 factor in a multi-pronged approach to protecting against common vulnerabilities. Take any course on secure development and they will, or should, mention input validation as a mitigating control for so many vulnerabilities. You might notice that it always comes with a but. Use input validation, but also use output … [Read more...] about Input validation is less about specific vulnerabilities
qa
Proxying localhost on FireFox
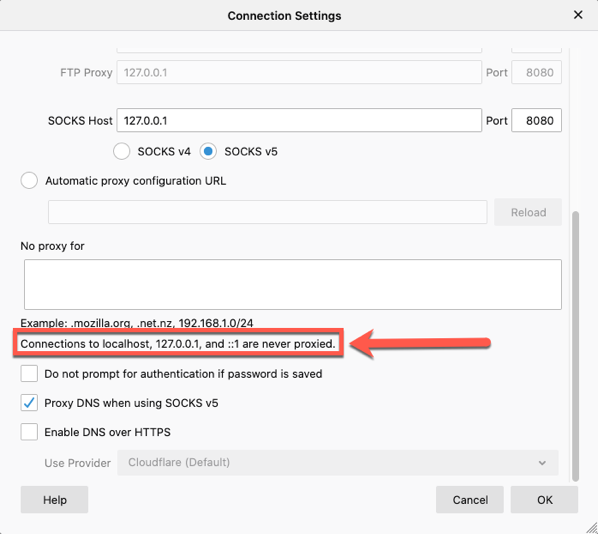
When you think of application security testing, one of the most common tools is a web proxy. Whether it is Burp Suite from Portswigger, ZAP from OWASP, Fiddler, or Charles Proxy, a proxy is heavily used. From time to time, you may find yourself testing a locally running application. Outside of some test labs or local development, this isn't really that common. But if you do find yourself testing a site on localhost, you may run into a roadblock in your browser. If you are using a recent version … [Read more...] about Proxying localhost on FireFox
Ep. 114: Investing in People for Better Application Security
In this episode, James talks about investing in the development teams to increase application security priorities. For more info go to https://www.developsec.com or follow us on twitter (@developsec). Join the conversations.. join our slack channel. Email james@developsec.com for an invitation. DevelopSec provides application security training to add value to your application security program. Contact us today to see how we can help. … [Read more...] about Ep. 114: Investing in People for Better Application Security
XSS in Script Tag
Cross-site scripting is a pretty common vulnerability, even with many of the new advances in UI frameworks. One of the first things we mention when discussing the vulnerability is to understand the context. Is it HTML, Attribute, JavaScript, etc.? This understanding helps us better understand the types of characters that can be used to expose the vulnerability. In this post, I want to take a quick look at placing data within a <script> tag. In particular, I want to look at how embedded … [Read more...] about XSS in Script Tag
Thinking about starting a bug bounty? Do this first.
Application security has become an important topic within our organizations. We have come to understand that the data that we deem sensitive and critical to our business is made available through these applications. With breaches happening all the time, it is critical to take reasonable steps to help protect that data by ensuring that our applications are implementing strong controls. Over the years, testing has been the main avenue for "implementing" security into applications. We have seen a … [Read more...] about Thinking about starting a bug bounty? Do this first.
Choosing Application Security Tools
There are lots of security tools available, so how do you know which one to pick? If your security team is not including the application teams in the decision, you run a big risk of failure. The security team does get the ability to form relationships with vendors. We see them at conferences. We know people that work there. Because our focus is on security, we know the tools that exist in our space and we have an idea of which ones may be better than others. Of course, this is often due to … [Read more...] about Choosing Application Security Tools