In this episode I talk about the evolving world of ransomware. I discuss a few examples of unique tactics the malicious actors are using to put pressure on organizations to pay the ransom. Referenced Articles: https://www.theregister.com/AMP/2024/04/30/finnish_psychotherapy_center_crook_sentenced/ https://www.darkreading.com/cyber-risk/hackers-weaponize-sec-disclosure-rules-against-corporate-targets https://www.theregister.com/2024/01/05/swatting_extorion_tactics/ For more info go to … [Read more...] about Ep. 121: Evolving Ransomware: Unique Tactics For Payment
breach
Apple Mail: Highlighting External Email Addresses
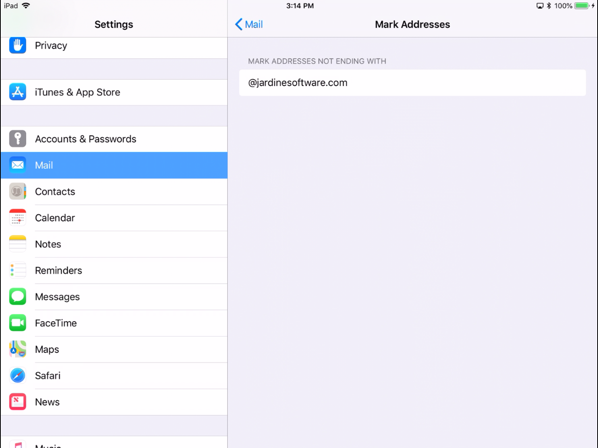
A simple error to make when sending an email with sensitive data is to send it to the wrong email address. Imagine you are sending some information to Dave down in accounting. When you fill out the email you start typing Dave and the auto-complete pops up and you select the first one (out of habit). You think you have selected the right Dave, but what if you didn't? How would you know that you were about to send potentially sensitive information outside of the organization? Apple Mail and iOS … [Read more...] about Apple Mail: Highlighting External Email Addresses
Equifax Take-aways
By now, you must have heard about the Equifax breach that may have affected up to 143 million records of user people's information. At this point, I don't think they can confirm exactly how many records were actually compromised, leading to going with the larger of the numbers just to be safe. While many are quick to jump to conclusions and attempt to Monday morning quarterback what they did or didn't do to get breached, I like to focus on what we can learn for our own organizations. There are a … [Read more...] about Equifax Take-aways
The 1 thing you need to know about the Daily Motion hack
It was just released that Daily Motion suffered a hack attack resulting in a large number of usernames and email addresses being released. Rather than focusing on the number of records received (the wow factor), I want to highlight what most places are just glancing over: Password Storage. According to the report, only a small portion of the accounts had a password associated with it. That is in the millions, and you might be thinking this is bad. It is actually the highlight of the story. … [Read more...] about The 1 thing you need to know about the Daily Motion hack
HIV clinic Data Breach: Thoughts and Takeaways
One of the most common ways for sensitive information to be released outside of an authorized environment is by simple, common mistakes made by employees. These types of incidents usually have no malicious intent and are generally innocent in nature. An example of this was recently reported regarding a newsletter that was sent out to HIV patients (and others) that the sender made a simple mistake. Rather than use the BCC for each recipients address, they used the CC field. For those that may … [Read more...] about HIV clinic Data Breach: Thoughts and Takeaways
Best Practices for Cyber Incident: DoJ Released Guide
Breaches and other security incidents are happening all of the time, and can happen to anyone. Do you know what to do if an incident occurs in your backyard? The Department of Justice recently released the Best Practices for Victim Response and Reporting of Cyber Incidents to help you understand the process. Looking through the 15 page document, there are quite a few great points that are made. Here are just a few examples of what are included. I encourage you to check out the entire … [Read more...] about Best Practices for Cyber Incident: DoJ Released Guide