Ok, so the title is a bit counter-intuitive. I recently saw an article talking about the end of support for some of the Internet Explorer versions out there (http://www.computerworld.com/article/3018786/web-browsers/last-chance-to-upgrade-ie-or-switch-browsers-as-microsofts-mandate-looms.html) and got to thinking about the number of sites that still require supporting some of these older versions of browsers. This is typically more common in the big corporate enterprises, as they have the … [Read more...] about Unsupported Browser Support
developer awareness
Untrusted Data: Quick Overview
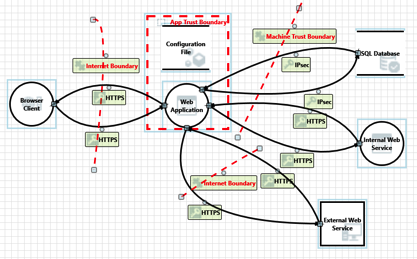
In the application security community it is common to talk about untrusted data. Talk about any type of injection attack (SQLi, XSS, XXE, etc) and one of the first terms mentions is untrusted data. In some cases it is also known as user data. While we hear the phrase all the time, are we sure everyone understands what it means? What is untrusted data? It is important that anyone associated with creating and testing applications understand the concept of untrusted data. Unfortunately, it can … [Read more...] about Untrusted Data: Quick Overview
What is a Penetration Test
You spend all day looking at requirements, creating functionality and doing some testing of the code you just created. You have been working for months on this application making sure it worked as expected. The testers have been diligently working to ensure that the requirements have been fulfilled and the application will work as expected and allow the end users the capability to solve a specific set of tasks. Then it happens... You find out that a penetration test is coming. … [Read more...] about What is a Penetration Test
Static Analysis: Analyzing the Options
When it comes to automated testing for applications there are two main types: Dynamic and Static. Dynamic scanning is where the scanner is analyzing the application in a running state. This method doesn't have access to the source code or the binary itself, but is able to see how things function during runtime. Static analysis is where the scanner is looking at the source code or the binary output of the application. While this type of analysis doesn't see the code as it is running, it has … [Read more...] about Static Analysis: Analyzing the Options
The Importance of Baselines
To understand what is abnormal, we must first understand what is normal. All too often we have overlooked the basic first step of understanding and recording our baselines. Whether it is for network traffic, data input, or binary sizes it is imperative we understand what is normal. Once we have an understanding of what normal is it becomes easier to start identifying abnormalities that can be of concern. Related podcast: Ep. 24: The Importance of Baselines Take a moment to think about … [Read more...] about The Importance of Baselines
Amazon XSS: Thoughts and Takeaways
It was recently identified, and Amazon was quick (2 days) to fix it, that one of their sites was vulnerable to cross-site scripting. Cross-site scripting is a vulnerability that allows an attacker to control the output in the user's browser. A more detailed look into cross-site scripting can be found on the OWASP site. Take-Aways QA could have found this Understand your input validation routines Check to make sure the proper output encoding is in place in every location user supplied … [Read more...] about Amazon XSS: Thoughts and Takeaways